Timings and parallelization
This section summarizes the options DFTK offers to monitor and influence performance of the code. For details on running DFTK on HPC systems, see also Using DFTK on compute clusters and Using DFTK on GPUs.
Timing measurements
By default DFTK uses TimerOutputs.jl to record timings, memory allocations and the number of calls for selected routines inside the code. These numbers are accessible in the object DFTK.timer. Since the timings are automatically accumulated inside this datastructure, any timing measurement should first reset this timer before running the calculation of interest.
For example to measure the timing of an SCF:
DFTK.reset_timer!(DFTK.timer)
scfres = self_consistent_field(basis, tol=1e-5)
DFTK.timer────────────────────────────────────────────────────────────────────────────────
Time Allocations
─────────────────────── ────────────────────────
Tot / % measured: 303ms / 40.0% 86.2MiB / 62.1%
Section ncalls time %tot avg alloc %tot avg
────────────────────────────────────────────────────────────────────────────────
self_consistent_field 1 121ms 100.0% 121ms 53.6MiB 100.0% 53.6MiB
LOBPCG 27 62.6ms 51.5% 2.32ms 12.1MiB 22.6% 460KiB
DftHamiltonian... 75 53.7ms 44.2% 716μs 4.38MiB 8.2% 59.8KiB
local 491 51.8ms 42.6% 106μs 100KiB 0.2% 208B
nonlocal 75 807μs 0.7% 10.8μs 317KiB 0.6% 4.22KiB
ortho! X vs Y 69 2.82ms 2.3% 40.9μs 1.18MiB 2.2% 17.5KiB
ortho! 146 1.63ms 1.3% 11.1μs 902KiB 1.6% 6.18KiB
rayleigh_ritz 48 2.61ms 2.1% 54.4μs 1.09MiB 2.0% 23.4KiB
ortho! 27 402μs 0.3% 14.9μs 136KiB 0.2% 5.03KiB
preconditioning 75 255μs 0.2% 3.41μs 20.4KiB 0.0% 278B
Update residuals 75 198μs 0.2% 2.64μs 36.3KiB 0.1% 496B
compute_density 9 29.8ms 24.5% 3.31ms 5.76MiB 10.7% 655KiB
symmetrize_ρ 9 24.3ms 20.0% 2.70ms 4.45MiB 8.3% 507KiB
energy_hamiltonian 10 14.3ms 11.8% 1.43ms 15.2MiB 28.3% 1.52MiB
ene_ops 10 12.7ms 10.4% 1.27ms 11.3MiB 21.1% 1.13MiB
ene_ops: xc 10 10.6ms 8.7% 1.06ms 5.55MiB 10.4% 568KiB
ene_ops: har... 10 1.44ms 1.2% 144μs 4.51MiB 8.4% 462KiB
ene_ops: non... 10 229μs 0.2% 22.9μs 148KiB 0.3% 14.8KiB
ene_ops: kin... 10 145μs 0.1% 14.5μs 96.1KiB 0.2% 9.61KiB
ene_ops: local 10 136μs 0.1% 13.6μs 937KiB 1.7% 93.7KiB
energy 9 9.18ms 7.6% 1.02ms 8.53MiB 15.9% 971KiB
energy: xc 9 7.22ms 5.9% 802μs 3.32MiB 6.2% 378KiB
ene_ops: hartree 9 1.27ms 1.0% 141μs 4.06MiB 7.6% 462KiB
ene_ops: nonlocal 9 242μs 0.2% 26.9μs 148KiB 0.3% 16.5KiB
ene_ops: kinetic 9 160μs 0.1% 17.8μs 87.9KiB 0.2% 9.77KiB
ene_ops: local 9 137μs 0.1% 15.2μs 843KiB 1.5% 93.7KiB
Anderson acceler... 8 2.30ms 1.9% 288μs 4.45MiB 8.3% 570KiB
ortho_qr 3 135μs 0.1% 44.9μs 101KiB 0.2% 33.7KiB
χ0Mixing 9 73.1μs 0.1% 8.12μs 30.4KiB 0.1% 3.38KiB
enforce_real! 1 55.7μs 0.0% 55.7μs 384B 0.0% 384B
────────────────────────────────────────────────────────────────────────────────The output produced when printing or displaying the DFTK.timer now shows a nice table summarising total time and allocations as well as a breakdown over individual routines.
Timing measurements have the unfortunate disadvantage that they alter the way stack traces look making it sometimes harder to find errors when debugging. For this reason timing measurements can be disabled completely (i.e. not even compiled into the code) by setting the package-level preference DFTK.set_timer_enabled!(false). You will need to restart your Julia session afterwards to take this into account.
Rough timing estimates
A very (very) rough estimate of the time per SCF step (in seconds) can be obtained with the following function. The function assumes that FFTs are the limiting operation and that no parallelisation is employed.
function estimate_time_per_scf_step(basis::PlaneWaveBasis)
# Super rough figure from various tests on cluster, laptops, ... on a 128^3 FFT grid.
time_per_FFT_per_grid_point = 30 #= ms =# / 1000 / 128^3
(time_per_FFT_per_grid_point
* prod(basis.fft_size)
* length(basis.kpoints)
* div(basis.model.n_electrons, DFTK.filled_occupation(basis.model), RoundUp)
* 8 # mean number of FFT steps per state per k-point per iteration
)
end
"Time per SCF (s): $(estimate_time_per_scf_step(basis))""Time per SCF (s): 0.008009033203124998"Options for parallelization
At the moment DFTK offers two ways to parallelize a calculation, firstly shared-memory parallelism using threading and secondly multiprocessing using MPI (via the MPI.jl Julia interface). MPI-based parallelism is currently only over $k$-points, such that it cannot be used for calculations with only a single $k$-point. There is also support for Using DFTK on GPUs.
The scaling of both forms of parallelism for a number of test cases is demonstrated in the following figure. These values were obtained using DFTK version 0.1.17 and Julia 1.6 and the precise scalings will likely be different depending on architecture, DFTK or Julia version. The rough trends should, however, be similar.
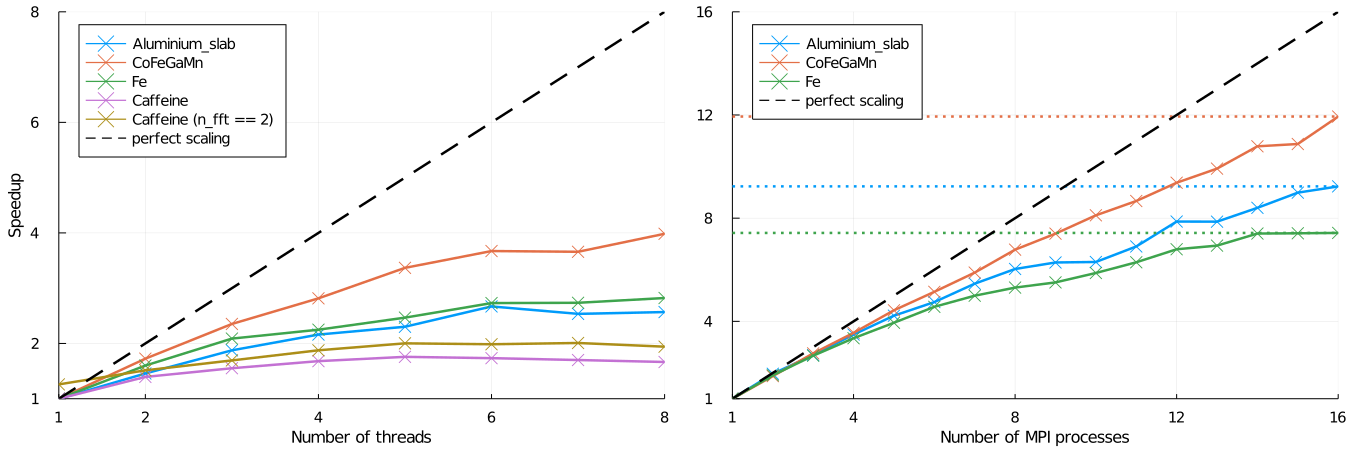
The MPI-based parallelization strategy clearly shows a superior scaling and should be preferred if available.
MPI-based parallelism
Currently DFTK uses MPI to distribute on $k$-points only. This implies that calculations with only a single $k$-point cannot use make use of this. For details on setting up and configuring MPI with Julia see the MPI.jl documentation.
First disable all threading inside DFTK, by adding the following to your script running the DFTK calculation:
using DFTK disable_threading()Run Julia in parallel using the
mpiexecjlwrapper script from MPI.jl:mpiexecjl -np 16 julia myscript.jlIn this
-np 16tells MPI to use 16 processes and-t 1tells Julia to use one thread only. Notice that we usempiexecjlto automatically select thempiexeccompatible with the MPI version used by MPI.jl.
As usual with MPI printing will be garbled. You can use
DFTK.mpi_master() || (redirect_stdout(); redirect_stderr())at the top of your script to disable printing on all processes but one.
While most standard procedures are now supported in combination with MPI, some functionality is still missing and may error out when being called in an MPI-parallel run. In most cases there is no intrinsic limitation it just has not yet been implemented. If you require MPI in one of our routines, where this is not yet supported, feel free to open an issue on github or otherwise get in touch.
Thread-based parallelism
Threading in DFTK currently happens on multiple layers distributing the workload over different $k$-points, bands or within an FFT or BLAS call between threads. At its current stage our scaling for thread-based parallelism is worse compared MPI-based and therefore the parallelism described here should only be used if no other option exists. To use thread-based parallelism proceed as follows:
Ensure that threading is properly setup inside DFTK by adding to the script running the DFTK calculation:
using DFTK setup_threading()This disables FFT threading and sets the number of BLAS threads to the number of Julia threads.
Run Julia passing the desired number of threads using the flag
-t:julia -t 8 myscript.jl
For some cases (e.g. a single $k$-point, fewish bands and a large FFT grid) it can be advantageous to add threading inside the FFTs as well. One example is the Caffeine calculation in the above scaling plot. In order to do so just call setup_threading(n_fft=2), which will select two FFT threads. More than two FFT threads is rarely useful.
Advanced threading tweaks
The default threading setup done by setup_threading is to select one FFT thread, and use Threads.nthreads() to determine the number of DFTK and BLAS threads. This section provides some info in case you want to change these defaults.
BLAS threads
All BLAS calls in Julia go through a parallelized OpenBlas or MKL (with MKL.jl. Generally threading in BLAS calls is far from optimal and the default settings can be pretty bad. For example for CPUs with hyper threading enabled, the default number of threads seems to equal the number of virtual cores. Still, BLAS calls typically take second place in terms of the share of runtime they make up (between 10% and 20%). Of note many of these do not take place on matrices of the size of the full FFT grid, but rather only in a subspace (e.g. orthogonalization, Rayleigh-Ritz, ...) such that parallelization is either anyway disabled by the BLAS library or not very effective. To set the number of BLAS threads use
using LinearAlgebra
BLAS.set_num_threads(N)where N is the number of threads you desire. To check the number of BLAS threads currently used, you can use BLAS.get_num_threads().
DFTK threads
On top of BLAS threading DFTK uses Julia threads in a couple of places to parallelize over $k$-points (density computation) or bands (Hamiltonian application). The number of threads used for these aspects is controlled by default by Threads.nthreads(), which can be set using the flag -t passed to Julia or the environment variable JULIA_NUM_THREADS. Optionally, you can use setup_threading(; n_DFTK) to set an upper bound to the number of threads used by DFTK, regardless of Threads.nthreads() (for instance, if you want to thread several DFTK runs and don't want DFTK's threading to interfere with that).
FFT threads
Since FFT threading is only used in DFTK inside the regions already parallelized by Julia threads, setting FFT threads to something larger than 1 is rarely useful if a sensible number of Julia threads has been chosen. Still, to explicitly set the FFT threads use
using FFTW
FFTW.set_num_threads(N)where N is the number of threads you desire. By default no FFT threads are used, which is almost always the best choice.